

The backbone of modern data architectures
In a technological ecosystem where responsiveness has become a strategic imperative, the ability to process information instantaneously distinguishes market leaders. Apache Kafka has established itself as the cornerstone of this revolution, transforming the way companies conceive data flow. Initially developed by LinkedIn engineers to overcome previously unsolvable scalability challenges, this distributed streaming system has transcended its original role to become the reference standard for contemporary infrastructures.
Today, the adoption of Kafka does not only address a technical need for message transport: it marks the transition towards event-driven architectures, capable of adapting in real-time to fluctuations in activity. By offering a robust, resilient, and highly extensible infrastructure, Kafka reconciles the performance requirements of the operational world with the deep analysis needs of Big Data. This article aims to decipher the fundamental mechanisms that make Kafka a pillar of modern data management and explore how it integrates into the heart of the most ambitious IT master plans.
What is Kafka?
Apache Kafka is more than just a simple transfer tool; it is a complete distributed platform whose expertise is built around four fundamental pillars:
- Messaging: it ensures fluid and secure message dissemination between heterogeneous systems;
- Real-time data management: it allows for the instantaneous processing of information flows as soon as they are emitted;
- Durable persistence: it guarantees the integrity and long-term conservation of events;
- Scalability: it offers the horizontal expansion capability essential for large-scale infrastructures.
Unlike traditional messaging middlewares such as RabbitMQ or ActiveMQ, Kafka is specifically architected to absorb massive volumes of data while maintaining extremely low latency and total resilience against failures.
It can be analyzed as a high-performance data pipeline, capable of transposing millions of events per second between critical applications.
A concrete illustration: the case of mobility leaders
In organizations such as Uber or Bolt, every digital interaction — whether it is a GPS position change, a financial transaction, or a trip estimate — must transit through Kafka. This centralization allows internal services to consume this data for:
- Visualization: dynamically displaying the map in real-time;
- Pricing optimization: calculating the ride price instantaneously;
- Security: identifying and blocking fraud attempts;
- Decision analysis: updating statistical performance indicators. Kafka operates here as the central nervous system, unifying all the company’s information flows.
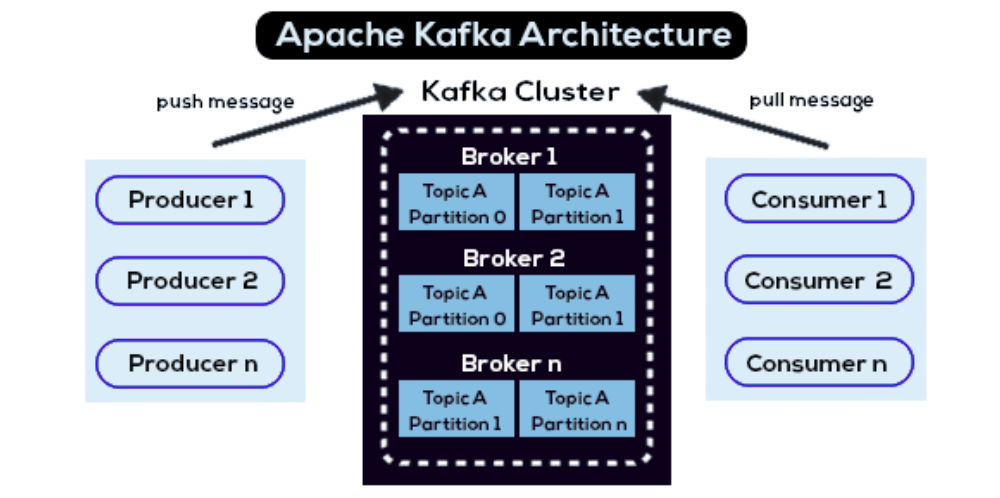
Technical architecture: fundamental concepts
To understand the power of Kafka, one must analyze the technological bricks that structure its ecosystem:
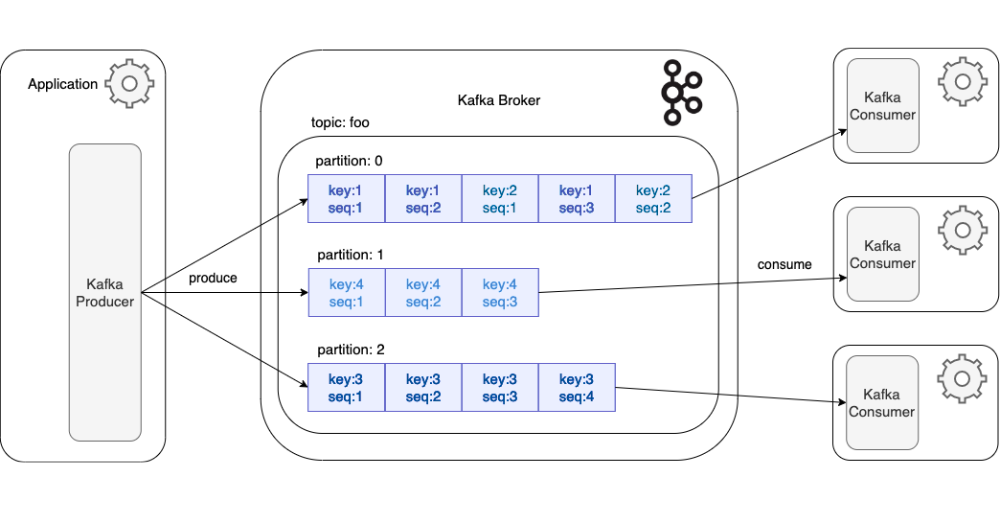
- Producers: these entities are responsible for emitting and injecting messages (or events) into the appropriate topics within the cluster.
- Topics: they represent the logical categories in which messages are classified. To ensure parallelism and scalability, each topic is subdivided into partitions.
- Brokers: these are the physical or virtual servers composing the Kafka cluster. Their mission is to store data and handle client requests.
- Consumers: these client applications subscribe to topics to read data. To optimize agility, they can be organized into « consumer groups » to intelligently distribute the reading load.
- Kafka Connect & Kafka Streams: the former facilitates automated integration with third-party systems (ETL, databases), while the latter allows for the transformation and analysis of flows in real-time, directly at the source.
Why has Kafka become the cornerstone of data?
The rise of Apache Kafka is explained by technical characteristics that meet the strictest requirements of technical departments:
Unrivaled performance and durable persistence
Thanks to intelligent partitioning and distribution across multiple brokers, Kafka processes millions of events per second without compromising on speed. Unlike classic queues that delete messages after reading, Kafka logs them to disk. This durability allows for the flow history to be replayed at will, a major asset for micro-services synchronization or the reconstruction of analytical states.
The catalyst for « event-driven » agility
Kafka fosters a high-performance micro-services architecture by establishing:
- Strict decoupling: services communicate without direct dependencies;
- Total asynchrony: processes no longer need to wait for an immediate response to continue their tasks;
- Native resilience: the platform ensures automatic recovery and service continuity, eliminating any risk of data loss.
Integration of Kafka in modern ecosystems
Considered as the central framework of technological infrastructures, or « data backbone », Apache Kafka goes beyond the simple role of message transporter to become the nervous system of organizations. It fulfills several critical functions that structure modern ecosystems.
A universal event streaming platform
Kafka establishes itself as a streaming platform capable of centralizing information flows from a multitude of heterogeneous sources. Instead of multiplying point-to-point connections, the tool collects data in a unified way to distribute it in real-time to all consuming applications. This aggregation capability breaks down data silos and ensures fluid and instantaneous dissemination across the entire enterprise.
A privileged communication hub for micro-services
In distributed architectures, Kafka radically transforms communication between services. By substituting direct and synchronous API calls with an event publication model, it establishes total decoupling.
This approach not only improves system observability but also enables unprecedented horizontal scalability: each service can evolve, stop, or restart independently without impacting the overall stability of the chain.
A strategic ingestion vector for Big Data and the Cloud
Thanks to the Kafka Connect ecosystem, the platform acts as a universal ingestion channel for massive storage environments. It continuously and automatically feeds Data Lakes, such as S3 or Google Cloud Storage, as well as modern Data Warehouses like Snowflake or BigQuery.
This native integration between transactional and analytical worlds accelerates the availability of data for Business Intelligence or Data Science needs.
A real-time transformation and analysis engine
Beyond transport, Kafka offers powerful processing capabilities through Kafka Streams or ksqlDB. It is no longer just about moving data, but transforming it during transit. Companies can thus perform complex operations such as stream joins, statistical aggregations, or critical anomaly detection over precise time windows, all without having to deploy heavy and costly ETL pipelines.
A distributed source of truth for historization
One of Kafka’s major strengths lies in its ability to retain event logs over very long periods, or even indefinitely. This characteristic allows the platform to be used as a distributed « source of truth ». In the event of a technical incident, this immutable memory allows the full flow history to be replayed to reconstruct the exact state of a micro-service, thus guaranteeing the data resilience and integrity indispensable to business operations.
A central hub between operational and analytical worlds
Finally, Kafka acts as the central pivot reconciling often compartmentalized universes: transactional processing systems (OLTP), analytical platforms (OLAP), Machine Learning, and micro-services. By serving as a single point of passage, it fluidifies exchanges and allows each brick of the information system to consume data that is always fresh, reliable, and consistent.
Conclusion
Apache Kafka has established itself as the sovereign tool for contemporary data architectures. Its ability to industrialize ingestion, storage, and distribution of data at a massive scale offers a robust and flexible communication model. Whether for streaming or integrating complex systems, it remains the most suitable answer to real-time challenges.
👉 Seek the expertise of our consultantsWhat is the fundamental difference between Kafka and a traditional Message Broker like RabbitMQ?
The major distinction lies in data management and scalability: while a classic broker like RabbitMQ generally deletes messages once they are consumed, Kafka stores them persistently on disk. This architecture allows Kafka to handle massive volumes of data with minimal latency while offering the possibility to replay event flows, a feature absent from traditional messaging systems.
Why is the concept of partition so critical for performance?
Partitioning is the engine of Kafka’s horizontal scalability: by splitting each topic into several partitions distributed across different brokers, Kafka allows for the parallelization of data reading and writing. It is this precise mechanism that allows for the processing of millions of messages per second and guarantees that the system can scale up without saturation.
Does Kafka really guarantee that no data is lost?
Yes, thanks to its persistence model and its distributed architecture: unlike volatile systems, Kafka retains messages durably. In the event of a service or broker failure, the platform ensures automatic recovery and service continuity, making it a reliable source of truth for critical architectures.
Is it possible to use Kafka to transform data without third-party tools?
Absolutely, that is the whole point of Kafka Streams and ksqlDB: these integrated tools allow for filtering, transforming, enriching, or aggregating data flows directly within the platform. This avoids having to deploy heavy external ETL pipelines and allows for the generation of metrics or the detection of critical events in real-time.
How does Kafka integrate with existing Cloud and Big Data infrastructures?
Kafka acts as a universal ingestion channel thanks to Kafka Connect: it can capture or send data to a multitude of destinations such as Data Lakes (S3, GCS) or modern Data Warehouses (Snowflake, BigQuery). It thus becomes the central pivot reconciling transactional systems, analytics, and Machine Learning.


