
Introduction: Why this decision is mission-critical in 2026
In 2026, integrating Generative AI into enterprise workflows is no longer about exploratory innovation; it is a fundamental strategic shift. Technical and Data leaders now face a pivotal dilemma: Fine-Tuning large language models versus implementing a RAG (Retrieval-Augmented Generation) approach. This choice directly dictates Total Cost of Ownership (TCO), business agility, scalability, and data traceability.
With corporate data sets constantly evolving, regulatory requirements tightening, and business needs becoming increasingly niche, how do you determine the right path? This article provides a comprehensive comparative analysis, enriched by real-world feedback and actionable recommendations to help CTOs, CDOs, and business stakeholders define their AI strategy.
Technical Fundamentals: RAG vs Fine-Tuning
What is RAG?
RAG (Retrieval-Augmented Generation) combines two core capabilities: intelligent information retrieval from a document knowledge base and text generation based on the most relevant results.
In this approach, the LLM remains unchanged; instead, it is dynamically augmented with up-to-date data, filtered according to the user’s specific query.
What is Fine-Tuning?
Fine-Tuning involves adapting a pre-trained language model (such as GPT or Llama) to a specific domain by further training it on a proprietary corporate dataset.
This process modifies the model’s internal parameters so that it internalises the unique terminology, style, or specific behaviours required by a business.

The Evolution of RAG into an Industrial Standard in 2026
From POC to Production: Technological Maturity and Adoption
In 2023-2024, RAG was often confined to the POC (Proof of Concept) stage. In 2026, it has matured into a standard architectural framework, fully integrated into MLOps/LLMOps pipelines featuring robust monitoring, versioning, and quality control.
RAG as Infrastructure: Centralised Knowledge and Document Governance
This approach promotes centralised knowledge governance while enabling the reuse of technical components across various use cases (from Customer Support and HR to Legal departments).
It significantly accelerates time-to-value, reduces operational costs, and strengthens data traceability.
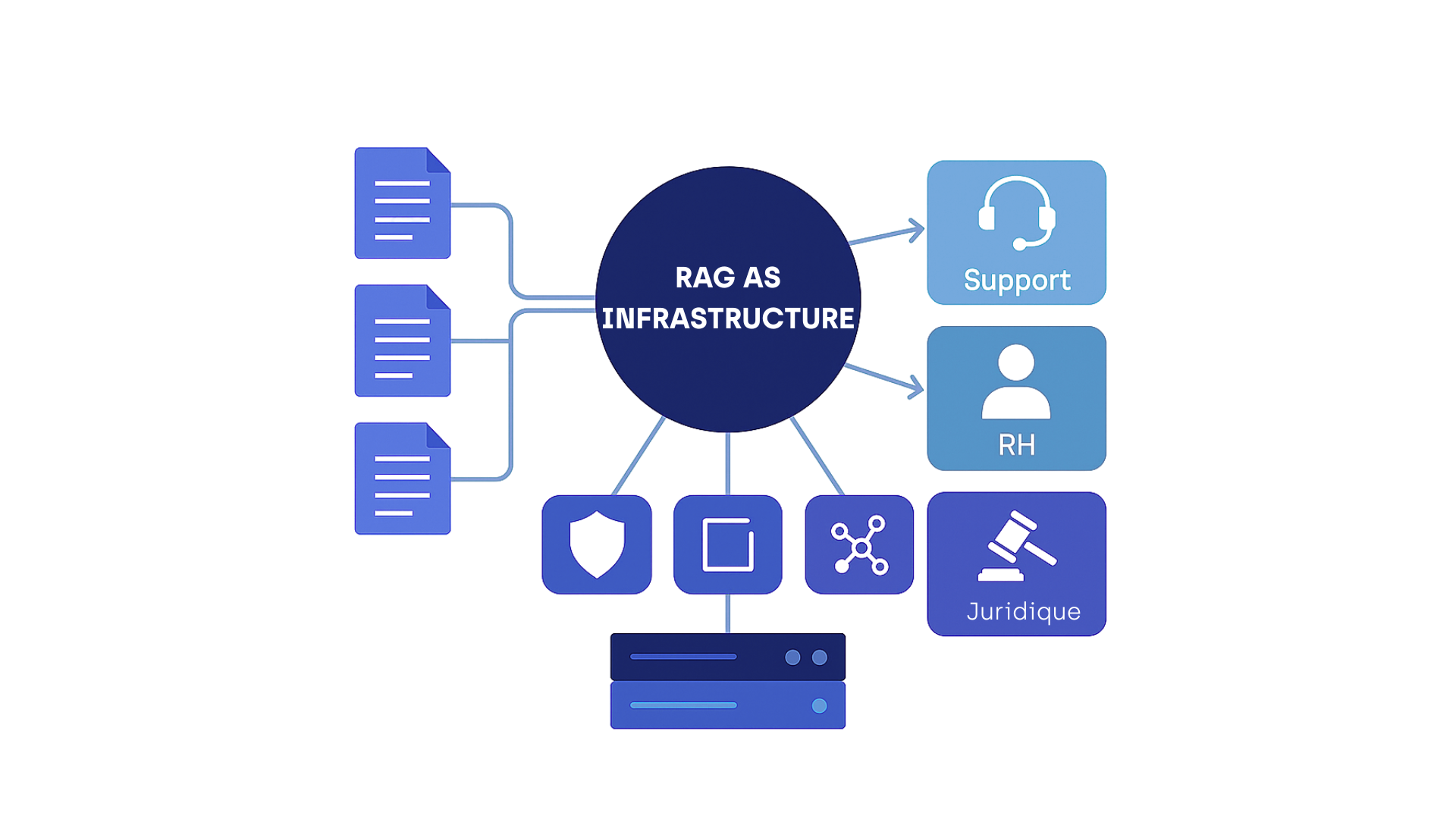
„Enterprise-Grade” RAG Architecture: The 5 Essential Components
A robust RAG system relies on a modular architecture aligned with business requirements. Here are the five essential building blocks for any serious production deployment.
Document Ingestion & Pre-processing
The quality of a RAG system depends first and foremost on its input corpus. This requires intelligent parsing, semantic enrichment, format standardisation, and rigorous document versioning.
Hybrid Vector Indexing & Metadata
A hybrid approach (combining dense and sparse retrieval) optimises response relevance. By integrating the intelligent use of metadata (e.g., date, author, department), you achieve highly granular business filtering.
Intelligent Retrieval Orchestration
The retrieval system must be adaptive, utilising mechanisms such as re-ranking, contextual fallback, and user profiling to ensure the most accurate data is surfaced.
Controlled & Contextualised Generation
The LLM must adhere to a specific editorial tone, response structure, and business rules. Implementing strict grounding is essential to prevent hallucinations and ensure the compliance of generated answers.
Observability & Feedback Loops
An enterprise RAG platform must include hallucination monitoring, request logging, and user feedback tools to facilitate the continuous improvement of response quality.
RAG vs Fine-Tuning: Comparing Pros and Cons
Choosing between RAG and Fine-Tuning depends on operational, technical, and economic criteria. Here are the primary differences you need to consider:
| Criteria | Fine-Tuning | RAG |
|---|---|---|
| Cost | High (Training, GPU infrastructure) | Moderate (No retraining required) |
| Flexibility | Low (Requires retraining for updates) | High (Corpus can be updated instantly) |
| Maintenance | Complex (Requires AI specialists) | Simplified (Managed via data pipeline) |
| Traceability | Low („Black box” model) | High (Source citations are visible) |
| Update Frequency | Low | High |
2025 Business Decision Matrix: 4 Key Criteria
In 2025, the choice between Fine-Tuning and RAG should not be based on technical criteria alone. It must be driven by an analysis of concrete business needs, documentary constraints, and regulatory requirements. Here are the 4 most decisive business criteria, each illustrated by an operational insight:
Document Update Frequency
The question to ask: How quickly does my business content evolve?
RAG is recommended if: Your documentation is in constant flux (e.g., HR policies, IT procedures, product sheets, internal guides).
- Every document change can be integrated without retraining a model.
- Generated responses remain up-to-date as long as the corpus is updated.
Fine-Tuning is discouraged if: Content changes frequently, as every update necessitates a costly retraining of the model.
Use Case Stability vs Volatility
The question to ask: Are my use cases well-defined and long-term, or are they constantly evolving?
Fine-Tuning is recommended if: The use case is well-defined, stable, and repetitive, such as:
- Automatic document classification.
- Standardised responses to a massive volume of queries.
- Generation of highly formatted or regulated content.
RAG is recommended if: The need is variable or exploratory, such as:
- Contextual search within reports.
- Business diagnostic support.
- Access to scattered or sector-specific knowledge bases.
Required Level of Control Over Responses
The question to ask: Do I need to be able to justify or prove every generated response?
RAG is recommended if:
- You require a high level of traceability.
- You must show the exact source used to generate the response.
- Your users require business-level verifiability (e.g., compliance, taxation).
Fine-Tuning is discouraged if: It is difficult to verify the model’s justifications (as responses are learned but not specifically sourced).
Regulatory Constraints and Security
The question to ask: Where must my data be hosted? What level of confidentiality is required?
RAG is recommended if:
- You have data sovereignty constraints.
- You want to control the hosting environment (Private Cloud or On-premise).
- You use open-source models like Mistral or Llama 3 to maintain full control.
Fine-Tuning is less suitable if:
- You rely on a closed-source model hosted externally (e.g., GPT-4 on Azure/OpenAI).
- You process sensitive data that cannot be exported.
Typical Use Cases by Approach
Use Cases Suited for Fine-Tuning
Fine-tuning is particularly relevant in the following contexts:
- Specialised Chatbots in closed environments, such as medical or legal assistants that require highly specific terminology.
- Generating normative content, such as formal tender responses or regulatory summaries.
- Embedded systems, where connecting to an external database is impossible or carries high risk.
- Large-scale B2C applications, where optimising performance at a low cost is paramount.
Ideal Use Cases for RAG
RAG excels whenever there is a need to industrialise access to evolving business knowledge, particularly in:
- Internal support (HR, IT, Legal).
- Business co-pilots for document management.
- Regulatory or competitive intelligence.
- Onboarding new employees via dynamic FAQs.
Identifying the right use case at the right time is a strategic exercise. MARGO’s AI consultants are here to help you map your use cases and define a pragmatic roadmap.
Case Study: MargoZilla, Internal RAG Assistant
At Margo, the AI assistant MargoZilla was designed to support our internal teams. It automatically answers employee questions regarding HR, IT, training, and internal events. Integrated with Google Drive, it delivers sourced and contextualised responses directly via Google Chat.
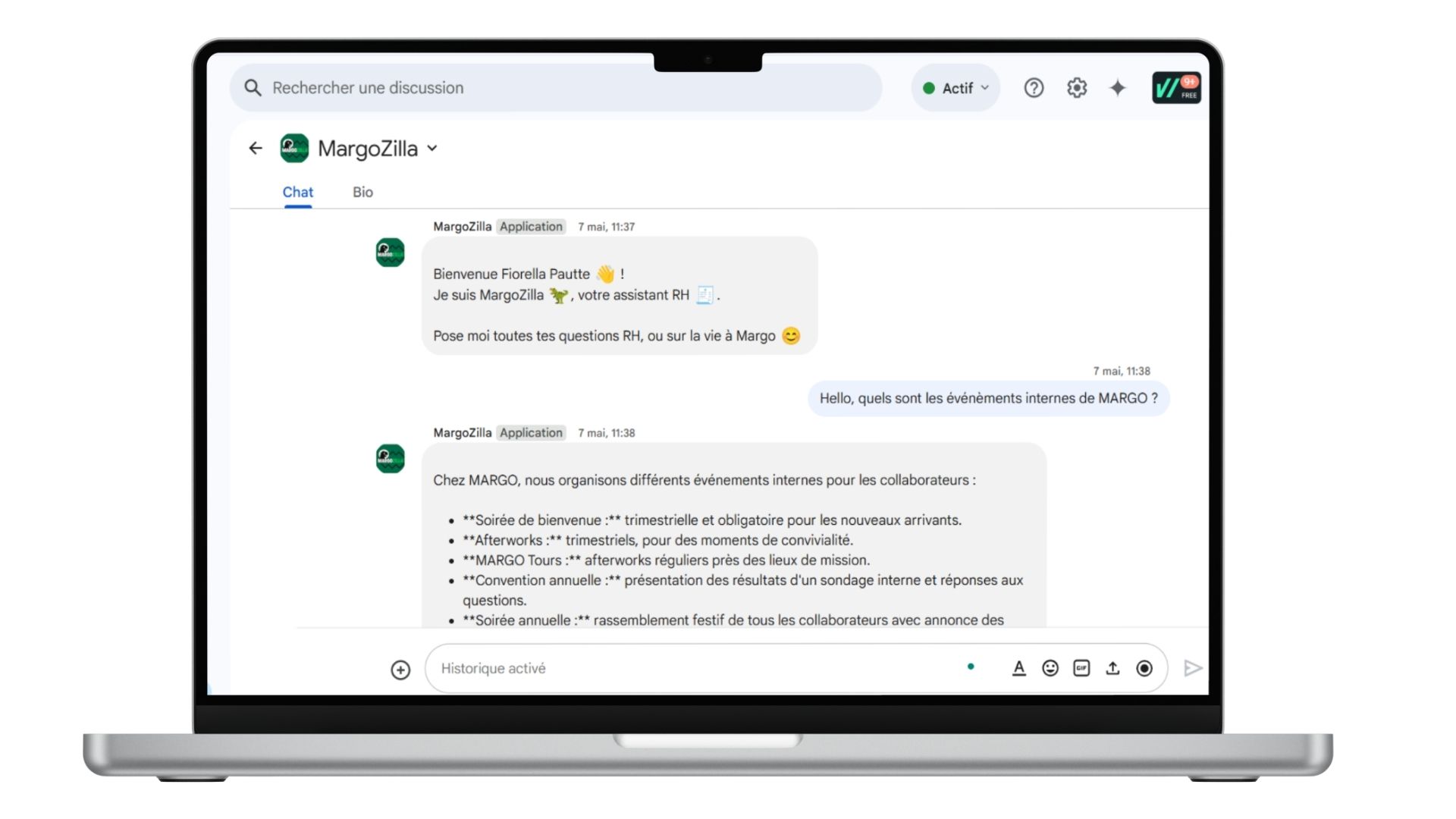
Key Constraints:
- Heterogeneous document corpus.
- Requirement for rigorous filtering: to prevent hallucinations and avoid sensitive information leaks.
- Seamless integration within Google Workspace.
Results:
- Reduction in HR/IT enquiries.
- Rapid adoption thanks to a simple UX.
- Significant time savings for operational teams.
Lessons Learned from the Field:
- Corpus structuring = The #1 quality factor.
- Metadata = Granular filtering and relevant responses.
- Automated pipeline = Always fresh data.
- Business integration = Facilitated adoption.
The RAG Technological Ecosystem in 2025
In 2025, the industrialisation of RAG projects relies on a technological chain that is robust, modular, and interoperable. Several tools and frameworks have established themselves as de facto standards, each covering a key link in the architecture.
LangChain: Intelligent Orchestration for LLM Workflows
LangChain has become the go-to framework for building call chains between an LLM, a search engine, a database, or an API.
LangServe / LangSmith: Integrated tools for exposing API endpoints and monitoring production chains.
- Extreme modularity (agents, tools, memory, etc.)
- Interconnection with all major models (OpenAI, Anthropic, Hugging Face, etc.)
- Advanced orchestration of sequential or parallel tasks
LlamaIndex: Advanced and Dynamic Corpus Management
Formerly GPT Index, LlamaIndex is a specialised tool for connecting a document corpus to an LLM. It excels at building high-performance, up-to-date indices.
- Intelligent ingestion of unstructured data
- Custom and contextual chunking
- Interconnected document graphs
Haystack: Robust NLP Pipeline with Native Traceability
Developed by Deepset, Haystack is an open-source framework focused on semantic search, augmented generation, and traceability.
- Native support for RAG architectures
- Performance monitoring and explainability of results
- Easy integration with Elasticsearch, OpenSearch, and Qdrant
Qdrant, Weaviate, FAISS: Vector Engines at the Heart of RAG
These vector databases are the „brains” of the RAG system. They convert documents into numerical vectors and retrieve the most relevant ones during a query.
- Qdrant: Open-source, advanced filtering, cloud-native – Contextual business support
- Weaviate: Integrated graphs, schema-first, REST+GraphQL API – Relational search
- FAISS: Ultra-high performance, GPU support, simple – High-performance, on-premise use cases
Business Criteria for Selection:
- Latency: Responsiveness within user interfaces.
- Filtering: Capability to cross-reference vectors and metadata.
- Infrastructure Costs: Optimised hosting solutions.
- GDPR Compliance: Sovereign Cloud vs. Public Cloud.
- On-premise Scenarios: FAISS and Qdrant are excellent candidates.
AI Convergence: Towards Autonomous Cognitive Assistants
The future of RAG extends beyond contextual text generation. We are witnessing a fusion with other emerging AI approaches, transforming RAG into true intelligent business co-pilots.
LLM Agents + RAG: Automating Complex Workflows
Frameworks such as LangChain Agents, CrewAI, and AutoGPT allow LLMs to become autonomous agents capable of:
- Planning a sequence of actions (research + analysis + response).
- Calling external APIs, such as a CRM database or an ERP system.
- Acting based on results, such as drafting a report, triggering a ticket, or generating a recommendation.
- Automatically generating a personalised training plan based on HR interviews.
- Compiling an activity report from business logs and emails.
Multimodality: RAG Beyond Text
The integration of multimodal capabilities transforms RAG into a versatile and immersive tool:
- Reading scanned PDFs, blueprints, and diagrams.
- Image processing (e.g., illustrated industrial manuals).
- Generating enriched content (graphs, diagrammes, visual interfaces).
- Industrial Maintenance: Recognising a part from a photo and generating a technical data sheet.
- Technical Support: Analysing a voice message and retrieving the correct documentation.
Live RAG + Knowledge Graphs
„Live RAG” connects augmented generation to real-time data sources: SQL databases, internal APIs, BI tools, etc.
The objective: To produce hybrid responses combining:
- Textual summaries.
- Live data or metrics.
Knowledge Graphs: These allow for structuring knowledge (entities and relationships), making responses more precise and deductive.
- Sales Management: Generating a client summary combined with their history and current KPIs.
- Financial Diagnostics: Reconciling accounting rules with real-time financial figures.
In Summary
RAG in 2025 is no longer just a document access tool, but a strategic foundation for building intelligent, reliable, adaptable, and interconnected assistants. It is now part of a mature technological ecosystem at the intersection of NLP, data engineering, autonomous agents, and knowledge graphs.
Need an AI co-pilot in your organisation?
Want to industrialise a POC or optimise an existing RAG system?
We secure your AI delivery, align technology with your challenges, and accelerate your data transformation.


