

L’épine dorsale des architectures de données modernes
Dans un écosystème technologique où la réactivité est devenue un impératif stratégique, la capacité à traiter l’information instantanément distingue les leaders de leur marché. Apache Kafka s’est imposé comme la pierre angulaire de cette révolution, transformant la manière dont les entreprises conçoivent la circulation des données. Initialement développé par les ingénieurs de LinkedIn pour surmonter des défis de scalabilité jusqu’alors insolubles, ce système de streaming distribué a transcendé son rôle originel pour devenir le standard de référence des infrastructures contemporaines.
Aujourd’hui, l’adoption de Kafka ne répond pas seulement à un besoin technique de transport de messages : elle marque la transition vers des architectures orientées événements (event-driven), capables de s’adapter en temps réel aux fluctuations de l’activité. En offrant une infrastructure robuste, résiliente et hautement extensible, Kafka permet de réconcilier les exigences de performance du monde opérationnel avec les besoins d’analyse profonde du Big Data. Cet article se propose de décrypter les mécanismes fondamentaux qui font de Kafka un pilier de la gestion de données moderne et d’explorer comment il s’intègre au cœur des schémas directeurs IT les plus ambitieux.
Qu’est-ce que Kafka ?
Apache Kafka ne se contente pas d’être un simple outil de transfert ; il s’agit d’une plateforme distribuée complète, dont l’expertise s’articule autour de quatre piliers fondamentaux :
- Le messaging : il assure la diffusion fluide et sécurisée de messages entre des systèmes hétérogènes;
- La gestion de données en temps réel : il permet le traitement instantané des flux d’informations dès leur émission;
- La persistance durable : il garantit l’intégrité et la conservation des événements sur le long terme;
- La scalabilité : il offre une capacité d’extension horizontale indispensable aux infrastructures de grande envergure.
À la différence des middlewares de messagerie traditionnels comme RabbitMQ ou ActiveMQ, Kafka est spécifiquement architecturé pour absorber des volumes massifs de données tout en maintenant une latence extrêmement faible et une résilience totale face aux pannes.
On peut l’analyser comme un pipeline de données haute performance, capable de transposer des millions d’événements par seconde entre des applications critiques.
Une illustration concrète : le cas des leaders de la mobilité
Dans des structures telles qu’Uber ou Bolt, chaque interaction numérique — qu’il s’agisse d’un changement de position GPS, d’une transaction financière ou de l’estimation d’un trajet — transite impérativement par Kafka. Cette centralisation permet aux services internes de consommer ces données pour :
- La visualisation : afficher dynamiquement la carte en temps réel;
- L’optimisation tarifaire : calculer le prix de la course instantanément;
- La sécurité : identifier et bloquer les tentatives de fraude;
- L’analyse décisionnelle : mettre à jour les indicateurs statistiques de performance. Kafka opère ici comme le système nerveux central, unifiant l’ensemble des flux d’informations de l’entreprise.
L’architecture technique : les concepts fondamentaux
Pour comprendre la puissance de Kafka, il convient d’analyser les briques technologiques qui structurent son écosystème:
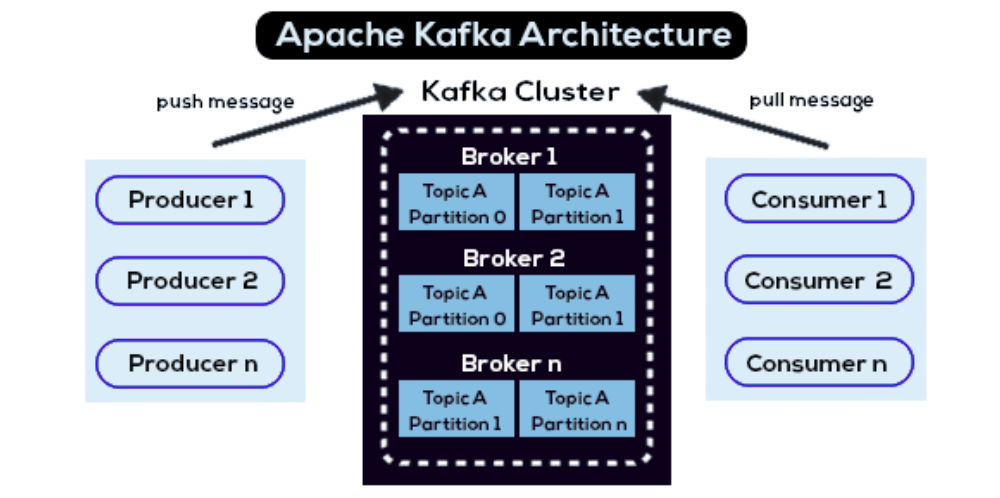
- Les Producers : ces entités sont chargées d’émettre et d’injecter les messages (ou événements) vers les topics appropriés au sein du cluster.
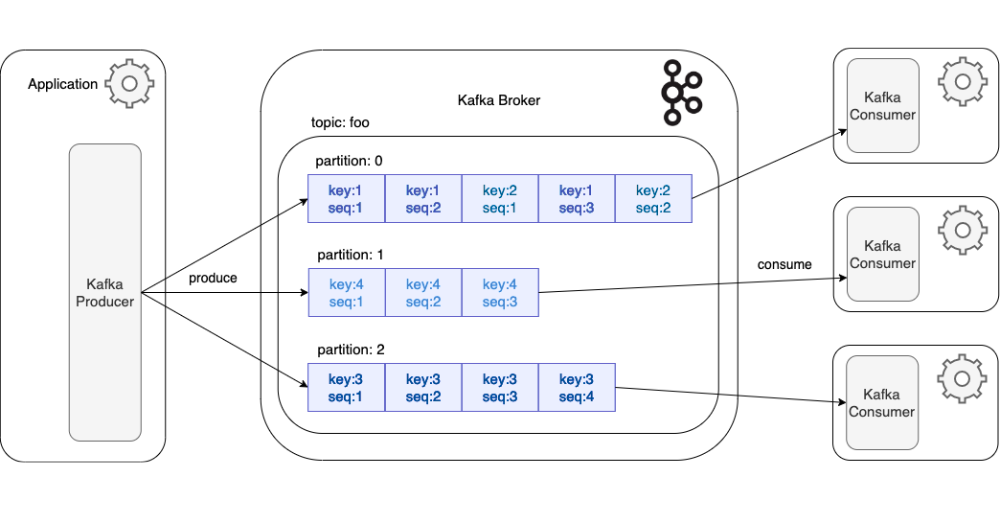
- Les Topics : ils représentent les catégories logiques dans lesquelles les messages sont classés. Afin de garantir le parallélisme et la scalabilité, chaque topic est subdivisé en partitions.
- Les Brokers : ce sont les serveurs physiques ou virtuels composant le cluster Kafka. Ils ont pour mission de stocker les données et de gérer les requêtes des clients.
- Les Consumers : ces applications clientes souscrivent aux topics pour lire les données. Pour optimiser l’agilité, ils peuvent être organisés en « consumer groups » afin de répartir intelligemment la charge de lecture.
- Kafka Connect & Kafka Streams : le premier facilite l’intégration automatisée vers des systèmes tiers (ETL, bases de données), tandis que le second permet de transformer et d’analyser les flux en temps réel, directement à la source.
Pourquoi Kafka est-il devenu la pierre angulaire de la Data ?
L’ascension d’Apache Kafka s’explique par des caractéristiques techniques qui répondent aux exigences les plus strictes des directions techniques :
Une performance inégalée et une persistance durable
Grâce à un partitionnement intelligent et une distribution sur plusieurs brokers, Kafka traite des millions d’événements par seconde sans compromis sur la rapidité. Contrairement aux files d’attente classiques qui suppriment les messages après lecture, Kafka les consigne sur disque. Cette durabilité permet de rejouer l’historique des flux à discrétion, un atout majeur pour la synchronisation des micro-services ou la reconstruction d’états analytiques.
Le catalyseur de l’agilité « Event-Driven »
Kafka favorise une architecture de micro-services performante en instaurant :
- Un découplage strict : les services communiquent sans dépendances directes;
- Une asynchronisme total : les processus n’ont plus besoin d’attendre de réponse immédiate pour poursuivre leurs tâches;
- Une résilience native : la plateforme assure une reprise automatique et une continuité de service, éliminant tout risque de perte de données.
L’intégration de Kafka dans les écosystèmes modernes
Considéré comme l’ossature centrale des infrastructures technologiques, ou « data backbone », Apache Kafka dépasse le simple rôle de transporteur de messages pour devenir le système nerveux des organisations. Il remplit plusieurs fonctions critiques qui structurent les écosystèmes modernes.
Une plateforme de streaming d’événements universelle
Kafka s’impose comme une plateforme de streaming capable de centraliser des flux d’informations provenant d’une multitude de sources hétérogènes. Au lieu de multiplier les connexions point à point, l’outil collecte les données de manière unifiée pour les distribuer en temps réel à l’ensemble des applications consommatrices. Cette capacité d’agrégation permet de briser les silos de données et d’assurer une diffusion fluide et instantanée à l’échelle de toute l’entreprise.
Un hub de communication privilégié pour les micro-services
Dans les architectures distribuées, Kafka transforme radicalement la communication entre les services. En substituant les appels API directs et synchrones par un modèle de publication d’événements, il instaure un découplage total.
Cette approche améliore non seulement l’observabilité du système, mais permet également une scalabilité horizontale sans précédent : chaque service peut évoluer, s’arrêter ou redémarrer de manière indépendante sans impacter la stabilité globale de la chaîne.
Un vecteur d’ingestion stratégique pour le Big Data et le Cloud
Grâce à l’écosystème Kafka Connect, la plateforme joue le rôle de canal d’ingestion universel vers les environnements de stockage massifs. Elle alimente de manière continue et automatisée les Data Lakes, tels que S3 ou Google Cloud Storage, ainsi que les Data Warehouses modernes comme Snowflake ou BigQuery.
Cette intégration native entre les mondes transactionnels et analytiques permet d’accélérer la mise à disposition de la donnée pour les besoins de Business Intelligence ou de Data Science.
Un moteur de transformation et d’analyse en temps réel
Au-delà du transport, Kafka offre de puissantes capacités de traitement grâce à Kafka Streams ou ksqlDB. Il ne s’agit plus seulement de déplacer la donnée, mais de la transformer durant son transit. Les entreprises peuvent ainsi réaliser des opérations complexes telles que des jointures entre flux, des agrégations statistiques ou la détection d’anomalies critiques sur des fenêtres temporelles précises, le tout sans avoir à déployer des pipelines ETL lourds et coûteux.
Une source de vérité distribuée pour l’historisation
L’une des forces majeures de Kafka réside dans sa capacité à conserver les logs d’événements sur de très longues périodes, voire indéfiniment. Cette caractéristique permet d’utiliser la plateforme comme une « source of truth » distribuée. En cas d’incident technique, cette mémoire immuable permet de rejouer l’historique complet des flux pour reconstruire l’état exact d’un micro-service, garantissant ainsi une résilience et une intégrité des données indispensables aux métiers.
Un hub central entre les mondes opérationnels et analytiques
Enfin, Kafka agit comme le pivot central réconciliant des univers souvent cloisonnés : les systèmes de traitement transactionnel (OLTP), les plateformes analytiques (OLAP), le Machine Learning et les micro-services. En servant de point de passage unique, il fluidifie les échanges et permet à chaque brique du système d’information de consommer une donnée toujours fraîche, fiable et cohérente.
Conclusion
Apache Kafka s’est imposé comme l’outil souverain pour les architectures data contemporaines. Sa capacité à industrialiser l’ingestion, le stockage et la distribution de données à une échelle massive offre un modèle de communication robuste et flexible. Que ce soit pour le streaming ou l’intégration de systèmes complexes, il demeure la réponse la plus adaptée aux défis du temps réel.
👉 Solliciter l’expertise de nos consultantsQuelle est la différence fondamentale entre Kafka et un Message Broker traditionnel comme RabbitMQ ?
La distinction majeure réside dans la gestion de la donnée et la scalabilité : alors qu’un broker classique comme RabbitMQ supprime généralement les messages une fois qu’ils sont consommés, Kafka les stocke de manière persistante sur disque. Cette architecture permet à Kafka de gérer des volumes massifs de données avec une latence minimale tout en offrant la possibilité de rejouer les flux d’événements, une fonctionnalité absente des systèmes de messagerie traditionnels.
Pourquoi le concept de partition est-il si critique pour la performance ?
Le partitionnement est le moteur de la scalabilité horizontale de Kafka : en découpant chaque topic en plusieurs partitions distribuées sur différents brokers, Kafka permet de paralléliser la lecture et l’écriture des données. C’est ce mécanisme précis qui autorise le traitement de millions de messages par seconde et garantit que le système peut monter en charge sans saturation.
Kafka permet-il réellement de garantir qu’aucune donnée ne soit perdue ?
Oui, grâce à son modèle de persistance et à son architecture distribuée : contrairement aux systèmes volatils, Kafka conserve les messages de manière durable. En cas de défaillance d’un service ou d’un broker, la plateforme assure une reprise automatique et une continuité de service, ce qui en fait une source de vérité fiable pour les architectures critiques.
Est-il possible d’utiliser Kafka pour transformer les données sans outils tiers ?
Absolument, c’est tout l’intérêt de Kafka Streams et ksqlDB : ces outils intégrés permettent de filtrer, transformer, enrichir ou agréger les flux de données directement au sein de la plateforme. Cela évite d’avoir à déployer des pipelines ETL externes lourds et permet de générer des métriques ou de détecter des événements critiques en temps réel.
Comment Kafka s’intègre-t-il avec les infrastructures Cloud et Big Data existantes ?
Kafka agit comme un canal d’ingestion universel grâce à Kafka Connect : il peut capter ou envoyer des données vers une multitude de destinations telles que les Data Lakes (S3, GCS) ou les Data Warehouses modernes (Snowflake, BigQuery). Il devient ainsi le pivot central réconciliant les systèmes transactionnels, l’analytique et le Machine Learning.


