
Article rédigé par Christophe El Harake, Practice Manager et expert en finance quantitative chez MARGO.
Les informations, opinions et analyses présentées par MARGO sont fournies exclusivement à titre informatif et pédagogique. Elles ne constituent ni une recommandation personnalisée, ni une incitation à acheter ou vendre des instruments financiers.
Introduction : pourquoi repenser le backtesting aujourd’hui ?
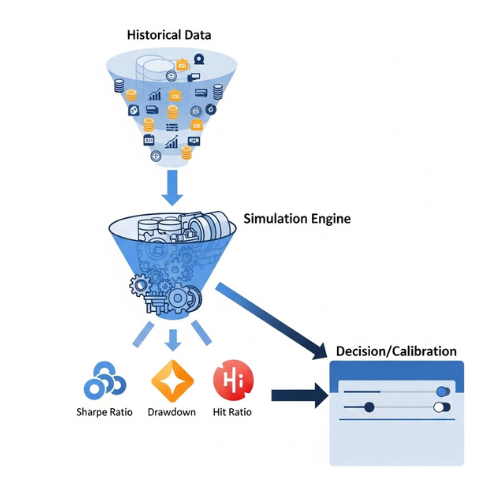
Le backtesting constitue un pilier central du développement des stratégies de trading quantitatif.
Il permet de valider, à l’aide de données historiques, la pertinence d’un modèle avant son déploiement en conditions réelles.
Cette étape joue un rôle critique dans le cycle de vie des stratégies, en fournissant des métriques clés (sharpe ratio, drawdown, hit ratio…) et en aidant à calibrer les paramètres décisionnels.
En somme, un backtest solide doit permettre de distinguer une performance statistiquement significative d’un simple bruit aléatoire.
Les limites des approches historiques de backtesting
Pourtant, les approches historiques classiques montrent aujourd’hui leurs limites.
De nombreux modèles reposent sur des hypothèses simplificatrices, voire irréalistes : liquidité parfaite, absence d’impact de marché, coûts de transaction constants…
À cela s’ajoutent des biais structurels bien connus :
- Survivorship bias
- Look-ahead bias
- Sur-optimisation (overfitting) via un ajustement excessif aux données d’apprentissage
Ces défauts peuvent conduire à une illusion de robustesse, source de désillusions lors du passage en production.
L’évolution du contexte de marché et l’essor des données alternatives
Le contexte de marché a profondément évolué.
La complexité croissante des instruments financiers, la vitesse d’exécution et l’interconnexion des marchés ont rendu les environnements plus dynamiques et moins stationnaires.
En parallèle, la montée en puissance des approches d’intelligence artificielle, notamment les modèles d’apprentissage automatique et de reinforcement learning, bouleverse les pratiques.
Ces modèles, souvent plus sensibles aux biais de données, nécessitent des outils de validation plus sophistiqués.
L’explosion des données alternatives (flux de news, réseaux sociaux, données ESG, géolocalisation…) ouvre de nouvelles opportunités, mais pose aussi la question de leur intégration rigoureuse dans un cadre de test fiable.
Vers une nouvelle génération de backtesting
Dans ce contexte, il devient essentiel de repenser en profondeur les méthodes de backtesting, pour bâtir des environnements plus réalistes, adaptatifs et résistants aux aléas de marché. Christophe El Harake, Practice Manager MARGO
Une nouvelle génération de backtesting est en train d’émerger : plus modulaire, plus robuste et mieux alignée avec les défis du quant trading contemporain.
État de l’art du backtesting quantitatif
Méthodologies classiques
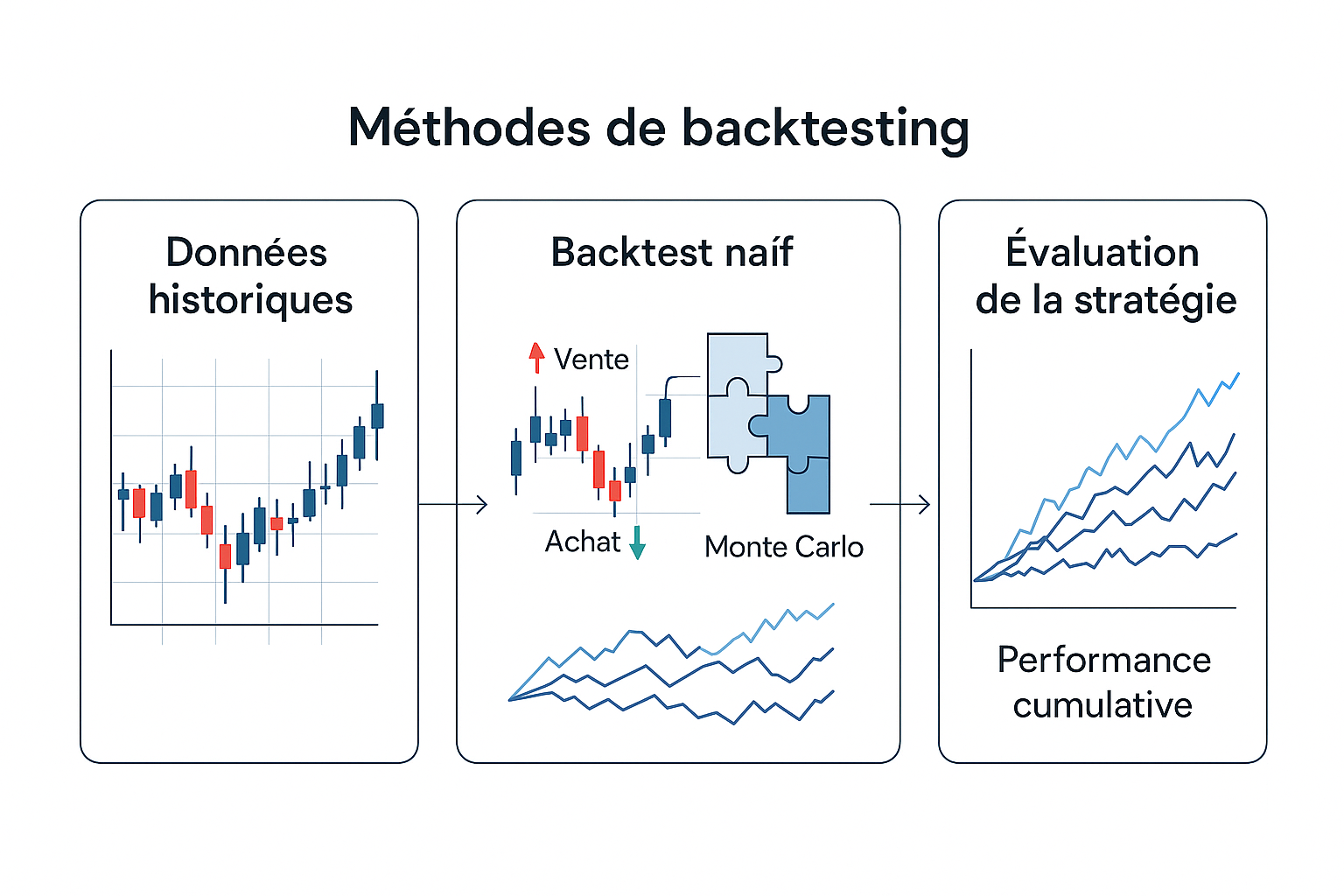
Le backtesting traditionnel repose sur des simulations de stratégie appliquées à des séries temporelles historiques.
Dans leur forme la plus simple, ces tests exploitent des données OHLC (Open, High, Low, Close) ou des données tick, selon la fréquence de la stratégie.
L’objectif est d’évaluer la rentabilité d’une logique de trading en conditions « réelles » mais rétrospectives.
Parmi les méthodes courantes :
- Backtest naïf avec règles fixes appliquées à un historique
- Bootstrapping : resampling des séries temporelles pour générer des trajectoires synthétiques
- Simulations Monte Carlo sur les rendements pour tester la stabilité de la stratégie dans différents univers de marché
Ces approches ont l’avantage d’être simples à mettre en œuvre et facilement interprétables.
Elles ont largement contribué à la démocratisation des stratégies quantitatives, notamment dans les hedge funds, chez les asset managers ou au sein des desks de proprietary trading.
Mais elles s’appuient souvent sur des hypothèses implicites qui peuvent poser problème :
- Stationnarité des séries de prix
- Liquidité illimitée et exécution immédiate
- Absence d’impact de marché ou de glissement (slippage)
- Indépendance des trades et absence de feedback loop
Failles structurelles
À mesure que les stratégies deviennent plus sophistiquées et que les marchés évoluent, ces modèles montrent leurs limites.
Plusieurs biais structurels nuisent à la validité des backtests classiques :
- Sur-optimisation (overfitting) : une stratégie calibrée à l’extrême sur les données passées peut sembler performante mais échouera en conditions réelles. Ce risque est aggravé lorsqu’on multiplie les tests d’hyperparamètres sans validation croisée rigoureuse.
- Look-ahead bias : survient lorsque des informations futures sont utilisées par erreur dans les décisions du modèle. Il peut être introduit par un mauvais alignement temporel des données ou par un accès trop précoce à des agrégats.
- Survivorship bias : les bases de données financières excluent souvent les titres disparus (faillites, retraits de cote…), faussant l’échantillon historique et donnant une image trop optimiste de la performance passée.
- Exécution irréaliste : les backtests supposent souvent une exécution parfaite sans latence ni impact de marché. Sur des stratégies haute fréquence ou à fort volume, ces aspects peuvent dégrader significativement les performances réelles.
- Changement de régime : les modèles backtestés sur une période donnée peuvent être inadaptés à d’autres contextes macroéconomiques ou microstructurels. L’hypothèse de stationnarité est rarement tenable sur plusieurs années.
Si les méthodologies classiques ont permis de poser les bases de l’évaluation des stratégies quantitatives, elles se heurtent aujourd’hui à la sophistication croissante des modèles et des données. Cette prise de conscience ouvre la voie à une refonte en profondeur des environnements de test. Christophe El Harake, Practice Manager MARGO
Les piliers d’une nouvelle génération de backtesting
La sophistication croissante des stratégies quantitatives et l’exigence d’une validation plus rigoureuse des performances ont poussé les acteurs du trading algorithmique à réinventer leurs méthodes de backtesting.
Ce renouveau ne se limite pas à des optimisations techniques : il repose sur une redéfinition des objectifs du backtest lui-même.
Désormais, il ne s’agit plus simplement de vérifier si une stratégie aurait fonctionné dans le passé, mais de tester sa robustesse face à l’incertitude, sa réactivité dans des conditions extrêmes, et surtout, sa compatibilité avec les contraintes d’exécution du monde réel.
Trois piliers structurent cette évolution.
Une simulation réaliste des conditions de marché
La première transformation majeure réside dans la volonté de reproduire fidèlement les dynamiques du marché, notamment à l’échelle microstructurelle.
Pourquoi c’est essentiel :
Un grand nombre de stratégies quantitatives, en particulier celles utilisées par les hedge funds systématiques ou les market makers électroniques, génèrent de la performance non pas par anticipation directionnelle du prix, mais par exploitation de micro-inefficiences.
Ces arbitrages se jouent à la milliseconde près, dans un environnement où le carnet d’ordres évolue en temps réel et où chaque action modifie l’état du marché.
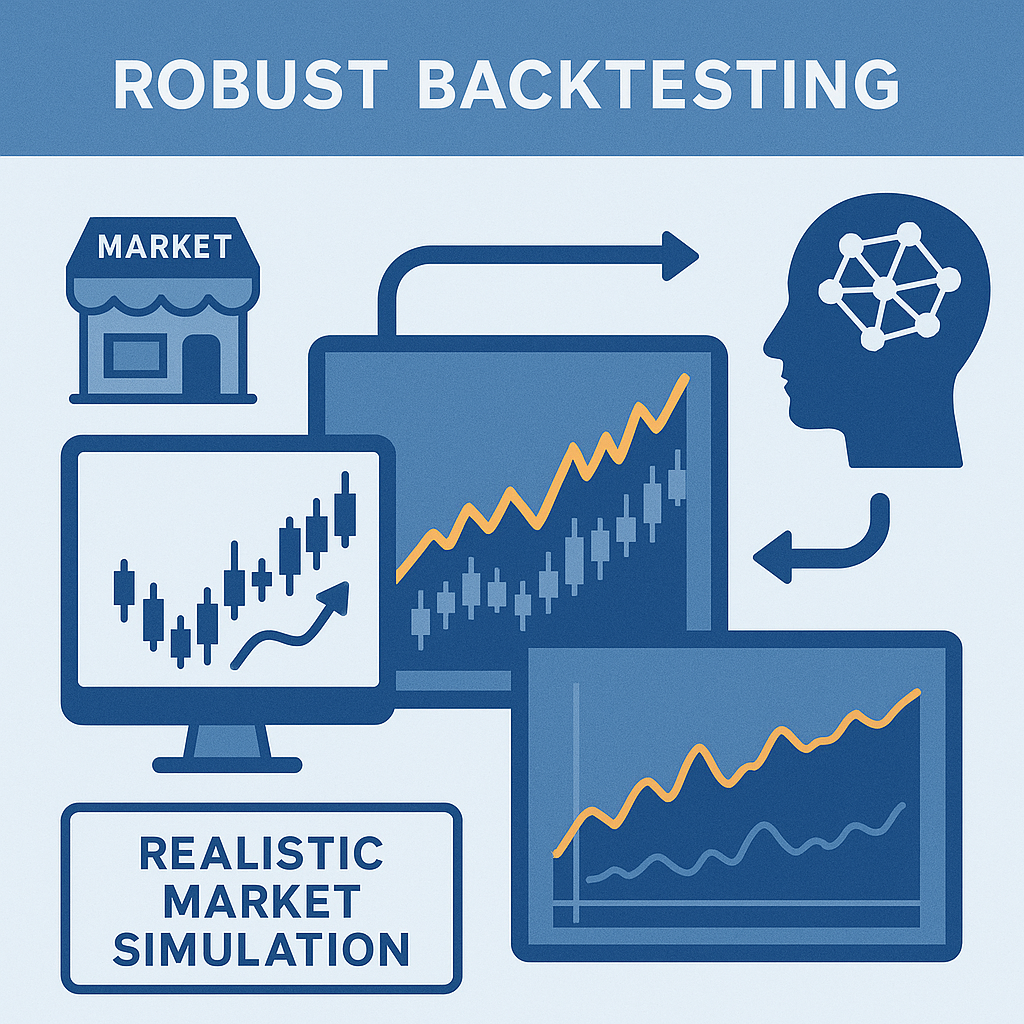
Ce que cela implique :
- Order Book Simulators : plutôt que de tester la stratégie sur une série de prix, on la confronte à une reconstitution du carnet d’ordres (Level 2), avec ses files d’attente, ses priorités d’exécution, et ses effets de latence. Par exemple, un algo qui soumet un ordre limite à l’achat à 9h30:00.123 doit attendre d’être exécuté en fonction de sa position dans la file, et peut être annulé avant d’être servi.
- Modèles d’impact de marché : on modélise l’effet de la stratégie elle-même sur les prix. Une stratégie de taille institutionnelle ne peut pas exécuter un ordre de 100 000 actions sans affecter le spread ou déclencher une réaction adverse du marché. Le backtest doit intégrer des modèles d’impact temporaire et permanent (cf. Almgren-Chriss).
- Modélisation des coûts réels : au lieu d’un spread constant et arbitraire, on utilise des données historiques ou simulées pour intégrer les coûts de transaction dynamiques, les frais de marché, les pénalités sur le taux d’annulation, et le slippage dû à l’agressivité de l’ordre.
Une stratégie de mean reversion intraday peut apparaître très rentable dans un backtest OHLC classique. Mais si l’exécution nécessite de prendre la liquidité sur le spread à chaque trade, ou si la file d’attente dans le carnet est trop profonde pour que l’ordre limite soit exécuté, la stratégie devient instantanément déficitaire en conditions réelles.
Hybridation avec des environnements d’exécution live
La deuxième évolution structurante consiste à rapprocher le backtesting de la production, en l’hybridant avec des environnements réels ou semi-réels.
Pourquoi ?
Les stratégies modernes sont de plus en plus complexes à valider en pure simulation.
Elles intègrent des signaux exogènes, des interactions entre portefeuilles, des décisions conditionnelles, et des effets technologiques comme la latence.
Il devient alors nécessaire de tester la stratégie dans un système opérationnel complet, sans exposer de capital réel.
Exemples d’approches :
- Paper trading augmenté : la stratégie tourne en temps réel sur des flux de marché live, mais les ordres ne sont pas envoyés à la bourse. On mesure en continu les performances, les ordres passés, les erreurs d’exécution ou de logique, dans un environnement proche de la production.
- Sandbox d’exécution : certains acteurs (par ex. : des dark pools ou des brokers algorithmiques) fournissent des environnements de test fermés mais réalistes, avec un carnet simulé, une latence artificielle, et des contraintes réglementaires, pour valider la stratégie de bout en bout.
- Tests synchronisés multi-stratégies : dans les firmes où plusieurs algos opèrent simultanément, le backtest moderne doit aussi simuler l’interférence entre stratégies : contention sur les ressources (capital, bande passante, priorité d’exécution), gestion du risque global, arbitrage inter-instruments.
Quelles sont les bénéfices ?
Cette hybridation permet :
- De tester les intégrations logicielles (OMS/EMS, reporting, risk checks).
- De capter les effets de bord techniques (ex : latence variable, erreurs de timestamp).
- De réduire drastiquement les écarts entre performance simulée et réelle (le fameux backtest/live slippage).
Approches probabilistes et adversariales
Enfin, un backtest moderne doit tester la résilience d’une stratégie, pas uniquement sa performance moyenne.
Il ne suffit plus de vérifier que le PnL est positif sur un historique : il faut savoir comment la stratégie réagit dans des univers alternatifs, parfois extrêmes, parfois inconnus.
Trois grandes approches :
Backtesting sous incertitude
La stratégie est testée sur un ensemble de scénarios générés par des modèles probabilistes.
Exemple : variation des spreads, de la volatilité, des régimes de corrélation entre actifs.
Objectif : obtenir une distribution de performance, avec des indicateurs de robustesse (worst-case PnL, CVaR, drawdown moyen…).
Simulation de marchés alternatifs via GANs
On entraîne des Generative Adversarial Networks sur des historiques réels pour générer des trajectoires de marché alternatives, mais crédibles.
Cela permet d’exposer la stratégie à des événements qui n’ont jamais eu lieu, mais qui pourraient survenir dans le futur.
Exemple : test d’un algo momentum sur un marché devenu illiquide pendant une crise de liquidité fictive.
Stress-testing algorithmique
On injecte manuellement ou automatiquement des événements extrêmes : flash crash, arrêt de cotation, gaps massifs à l’ouverture, publication d’un taux inattendu, rupture de parité.
Le système de backtest devient un outil de simulation de crise, et non plus seulement d’optimisation.
Quels sont les intérêts ?
Ces approches permettent de répondre à des questions qu’un backtest classique ne couvre pas :
- Que se passe-t-il si les corrélations inter-actifs se retournent brutalement ?
- Ma stratégie est-elle dépendante d’un seul régime de volatilité ?
- Puis-je détecter automatiquement les moments où elle devient dangereuse ou inefficace ?
La nouvelle génération de backtesting se veut plus réaliste, plus rigoureuse et plus prospective.
Elle combine des modèles de microstructure, des infrastructures de simulation avancées, et des approches probabilistes pour confronter la stratégie à la complexité du réel et à l’incertitude du futur.
Le backtest ne devient pas obsolète. Il devient une simulation stratégique à haute fidélité, pensée comme un outil de validation, de stress, et d’alignement entre recherche quant, développement technologique et contraintes opérationnelles.
Le rôle des données : cap vers des backtests augmentés
Inclusion des données alternatives
L’un des marqueurs forts de la nouvelle génération de backtesting est l’intégration massive de données alternatives, autrement dit des sources d’information non financières ou non conventionnelles, souvent issues du web, des réseaux sociaux, ou de capteurs exogènes.
Ces données ouvrent la voie à de nouveaux signaux de marché, parfois faibles, mais potentiellement très différenciants.

Parmi les principales sources intégrées aujourd’hui :
- Données de sentiment issues de forums financiers (Reddit, Stocktwits), de Twitter, ou d’analyses de presse via des modèles de traitement du langage naturel (NLP) ;
- Données issues du web scraping : analyse du contenu des sites e-commerce, de la fréquentation de plateformes, des mentions de marques ou de produits ;
- Données ESG et extra-financières : controverses d’entreprise, scores RSE, impact environnemental ;
- Données issues de capteurs ou d’images : satellites (trafic portuaire, activité industrielle), tracking GPS, signaux climatiques.
Ces données sont de plus en plus utilisées dans des stratégies de nowcasting, d’arbitrage comportemental, ou de diversification intersectorielle.
Elles permettent par exemple d’anticiper une révision d’estimation de bénéfice, une anomalie sectorielle, ou une rotation de style de marché (value/growth, risk-on/risk-off).
Mais leur intégration dans un framework de backtest soulève plusieurs risques structurels majeurs :
- Biais de publication : les données alternatives sont rarement standardisées. Leur disponibilité historique peut être incomplète ou reconstruite a posteriori, ce qui introduit des erreurs sur les timestamps réels.
- Look-ahead bias latent : dans les jeux de données complexes, il est fréquent d’utiliser une information qui, bien que datée du jour T, n’était en réalité disponible qu’à T+1 dans la base de données.
- Sur-ajustement aux signaux faibles : les signaux alternatifs, souvent très bruités, peuvent conduire à des performances impressionnantes dans le backtest, via une sur-optimisation involontaire.
- Corrélation spurious : la multiplication de sources hétérogènes augmente le risque d’identifier des corrélations sans lien de causalité.
Pour limiter ces biais, plusieurs bonnes pratiques doivent être systématisées :
- Utiliser des datasets historisés avec timestamps natifs, reflétant la date de réception du signal, pas sa date de publication ;
- Appliquer une logique de pipeline délayé, simulant les délais de traitement et de digestion du signal par la stratégie ;
- Tester chaque donnée alternative comme un facteur indépendant, dans des backtests séparés, avant toute agrégation avec d’autres signaux ;
- Introduire une composante probabiliste ou floue à la donnée pour mieux simuler son incertitude intrinsèque.
Data lineage et versioning
L’introduction de données massives et évolutives dans les backtests impose un changement profond de paradigme : la gestion des données devient aussi importante que le code de la stratégie lui-même.
Le data lineage, ou traçabilité des données, vise à pouvoir répondre à une question simple :
Quelles données exactes ont été utilisées pour produire ce backtest, et dans quel état ?
Dans une approche moderne, il ne suffit pas de stocker des fichiers CSV ou des snapshots bruts. Il faut construire une chaîne de transformation explicite, qui décrit :
- La source brute de la donnée (API, base de marché, fournisseur tiers) ;
- Les étapes de traitement intermédiaire (nettoyage, agrégation, enrichissement) ;
- Les paramètres de transformation (fenêtre glissante, normalisation, capping, imputation) ;
- La version de chaque composant du pipeline (code, modèle de preprocessing, configuration).
Ce besoin est amplifié dans les environnements collaboratifs, où plusieurs équipes doivent pouvoir auditer ou reproduire les résultats.
Le moindre écart dans une source ou un traitement peut fausser les performances observées.
De plus, il faut distinguer les jeux de données de test des jeux de données de production. La gouvernance des deux doit être découplée :
- Les données de test doivent être gelées, versionnées, et indépendantes des flux de données actuels ;
- Les données de production doivent suivre un circuit de validation rigoureux, avec alerting en cas de changement de format, de distribution, ou de fréquence.
Les outils issus du monde MLOps deviennent ainsi de plus en plus pertinents :
- DVC (Data Version Control) permet de versionner des jeux de données comme du code source ;
- MLflow assure la traçabilité des expérimentations, des modèles et des métriques associées ;
- LakeFS ou Pachyderm permettent de construire des data lakes versionnés.
Cette discipline du data lineage permet notamment :
- De rejouer un backtest à l’identique, même plusieurs mois plus tard ;
- D’expliquer à un auditeur pourquoi une stratégie a été validée à partir d’un certain jeu de données ;
- D’identifier des biais ou des erreurs ex post, en retraçant l’origine exacte d’un signal ou d’un comportement aberrant.
Vers une infrastructure de backtesting modulaire et collaborative
L’évolution des infrastructures de backtesting : vers des systèmes industriels
L’évolution des méthodes de backtesting ne peut être dissociée de l’évolution de l’infrastructure qui les supporte.
À mesure que les stratégies deviennent plus complexes, les données plus massives et les contraintes réglementaires plus strictes, le backtest ne peut plus être un simple script exécuté sur une machine locale.
Il devient un système logiciel à part entière, intégré dans un écosystème de développement, de validation et de production.
Cette mutation impose une approche modulaire, scalable, traçable, en un mot : industrielle.
Containerisation : garantir la reproductibilité des résultats
L’architecture moderne d’un environnement de backtesting repose désormais sur des fondations techniques robustes, inspirées des pratiques DevOps et des infrastructures de cloud computing.
La première brique essentielle est la containerisation des environnements via des technologies comme Docker.
Elle permet d’encapsuler l’ensemble des dépendances (bibliothèques, versions de Python, configurations systèmes) dans un environnement isolé, réplicable à l’identique, sur n’importe quelle machine.
Cela résout l’un des grands problèmes historiques du backtesting : les résultats qui varient d’un poste à un autre, ou qui deviennent impossibles à reproduire quelques semaines plus tard.
Cloud computing et architecture modulaire des backtests quantitatifs
Dans cette logique, les frameworks cloud-native, qu’ils soient déployés sur Kubernetes, sur des plateformes comme AWS Lambda ou Google Cloud Run, permettent de découpler le calcul des backtests en services indépendants, appelés via API.
On ne travaille plus sur un monolithe mais sur une architecture modulaire, où chaque composant (gestion des données, calcul du PnL, stratégie, moteur de simulation, reporting) peut évoluer de manière indépendante, être testé isolément, et être réutilisé dans d’autres contextes.

Intégrer le backtesting dans une chaîne CI/CD automatisée
Cette modularité facilite grandement l’intégration du backtest dans le cycle de vie complet des stratégies quantitatives.
Désormais, un backtest n’est plus un outil ponctuel en amont du déploiement, mais un maillon intégré d’une chaîne CI/CD (Continuous Integration / Continuous Deployment), au même titre que le code d’un modèle ou les outils de risk management.
À chaque modification du code de la stratégie, un pipeline automatisé peut re-lancer les backtests unitaires, valider les métriques attendues, générer un rapport d’analyse, et alerter en cas de dérive.
On parle ici de monitoring du comportement de la stratégie, non plus uniquement en production, mais dès les phases de développement.
Versionner les données et les modèles avec MLflow et DVC
Pour rendre ce système viable, il faut des outils de gestion du cycle de vie des modèles et des données.
C’est ici que des solutions comme MLflow, DVC ou Weights & Biases prennent tout leur sens.
Elles permettent de versionner les modèles, de suivre les hyperparamètres testés, de stocker les résultats intermédiaires, et d’organiser l’expérimentation de manière rigoureuse.
Un quant peut ainsi revenir à une version antérieure d’une stratégie, comprendre pourquoi elle avait été validée, et rejouer le backtest avec exactitude — un atout précieux dans un cadre de contrôle interne ou d’audit externe.
Faciliter la collaboration entre data scientists, développeurs et traders
Mais l’infrastructure ne doit pas seulement être technique : elle doit aussi faciliter la collaboration entre les différents acteurs de la chaîne de valeur.
Le backtesting est souvent un carrefour entre les data scientists qui conçoivent les modèles, les développeurs qui les implémentent, et les traders ou analystes qui en exploitent les résultats.
Trop souvent encore, ces équipes travaillent en silos, avec des langages, des outils et des priorités différentes.
Le rôle stratégique du quant dev dans la conception des environnements de test
Le rôle du quant dev devient alors stratégique.
À l’intersection de la finance, de la data et du développement logiciel, il conçoit des outils de backtesting qui traduisent les besoins métier dans des systèmes techniques fiables.
Il s’assure que les stratégies sont codées selon des standards robustes, que les métriques sont bien définies, que les logs sont exploitables.
Il construit des interfaces claires, documentées, versionnées, souvent avec des dashboards interactifs ou des notebooks Jupyter intégrés, pour que chaque partie prenante puisse interagir avec les résultats selon son propre niveau d’abstraction.
Traçabilité, documentation et audit : des exigences renforcées
Cette collaboration s’appuie également sur des bonnes pratiques de documentation, de tests unitaires, et de gouvernance du code.
Un backtest qui ne peut être expliqué ou reproduit n’a plus sa place dans un environnement professionnel.
Il doit être traçable, justifiable, et auditable, autant pour des raisons de contrôle interne que pour satisfaire à des exigences réglementaires croissantes, notamment en matière de transparence algorithmique.
En somme, la nouvelle infrastructure de backtesting n’est plus un outil d’expérimentation isolé. Elle devient une plateforme collaborative, modulaire et automatisée, qui articule les efforts des équipes techniques, quantitatives et métiers autour d’un objectif commun : produire des stratégies performantes, robustes, et pleinement maîtrisées dans leur cycle de vie. Christophe El Harake, Practice Manager MARGO
Études de cas : innovations concrètes sur le terrain
Pour illustrer concrètement les mutations en cours dans l’univers du backtesting quantitatif, il est utile d’examiner des cas réels ou inspirés de problématiques observées sur le terrain.
Ces exemples montrent comment les acteurs du trading algorithmique intègrent les piliers du backtest nouvelle génération, réalisme d’exécution, scénarisation, données alternatives, robustesse probabiliste, dans leurs environnements de R&D et de production.
🟢 Exemple 1 : Simulation d’un market maker intraday dans un environnement à latence variable
Dans le cadre d’une stratégie de market making intraday sur un marché d’options listées, une équipe quantitative développe un algorithme chargé de fournir en continu des cotations bid/ask sur plusieurs dizaines d’instruments.
La stratégie repose sur l’idée classique de capter le spread tout en maintenant une exposition delta-neutre, avec un réajustement dynamique du prix théorique en fonction de la vol surface.
Mais en conditions réelles, cette stratégie se heurte à plusieurs contraintes structurelles :
- La latence de traitement des ordres varie selon la charge serveur et le réseau ;
- La position dans la file d’attente sur le carnet détermine fortement la probabilité d’exécution ;
- Le coût d’exécution réel dépend du cancel rate et des pénalités appliquées par l’exchange.
Dans un backtest classique, cette stratégie afficherait des performances très élevées : spreads captés sans frictions, exécutions parfaites, pas d’impact de marché. Mais dans un environnement de simulation avancé, la réalité est toute autre.
Les équipes ont donc mis en place un simulateur de carnet d’ordres L2, reproduisant les dynamiques microstructurelles avec une granularité milliseconde.
Ce moteur prend en compte la latence réseau (variable selon les heures de la journée), la congestion des flux d’ordres, et la probabilité réelle d’exécution en fonction du positionnement temporel des quotes.
Les ordres sont placés dans un carnet simulé, avec un matching en FIFO et une file dynamique concurrente d’ordres virtuels émis par d’autres algorithmes simulés (adversaires).
➡️ Résultat : la stratégie initialement très performante se révèle en fait extrêmement sensible à la latence effective. Une simple dérive de 5ms sur le round-trip order/ack provoque une baisse de 70 % du taux d’exécution profitable.
Le backtest enrichi permet non seulement de détecter cette fragilité invisible autrement, mais aussi de calibrer dynamiquement les paramètres d’agressivité de la quote selon les pics de latence.
Ce niveau de simulation ouvre également la voie à une meilleure gestion du cancel rate et à une adaptation des priorités d’exécution sur différents exchanges en fonction des conditions du jour.
🟠 Exemple 2 : Stress-test d’une stratégie basée sur le sentiment Twitter face à des événements exogènes
Un fonds systématique développe une stratégie exploitant le sentiment exprimé sur Twitter pour anticiper les mouvements de certaines actions technologiques très suivies par les investisseurs particuliers.
Le modèle repose sur une analyse NLP en temps réel : les tweets liés à un ticker donné sont analysés, scorés, agrégés, et convertis en signaux de biais directionnel à court terme.
Le backtest sur les deux dernières années montre de bonnes performances, en particulier sur des valeurs à fort volume comme Tesla, AMD ou Palantir.
Mais l’équipe décide de tester la robustesse du modèle face à des événements exogènes non vus dans l’historique, comme une régulation brutale des réseaux sociaux, un gel de compte influent, ou un décalage massif entre sentiment exprimé et réalité de marché.
Un module de stress testing narratif est alors mis en place. Il consiste à injecter dans le backtest des scénarios simulés tels que :
- Une suppression temporaire de Twitter pendant 24h (simulée via une interruption brutale du flux de données sentiment) ;
- Une campagne de désinformation massive, modélisée par un renversement artificiel du score de sentiment ;
- Un “shadow ban” algorithmique sur un influenceur clé, réduisant l’impact de ses messages dans le modèle.
➡️ Ces scénarios permettent de mesurer l’élasticité du modèle aux perturbations de sa source de données principale.
Il apparaît que la stratégie, bien que performante dans des conditions normales, devient dangereusement directionnelle en cas de sentiment inversé.
De plus, l’algorithme tend à amplifier les mouvements erratiques lorsque les volumes de tweets chutent, car le modèle surpondère quelques signaux résiduels.
Grâce à ce backtest scénarisé, l’équipe introduit une couche de filtrage probabiliste sur la fiabilité du signal et développe un système de failover vers d’autres sources (forums Reddit, flux de presse) en cas de panne ou de manipulation détectée.
🔵 Exemple 3 : Backtest sous incertitude avec un générateur de scénarios GAN
Une équipe quant d’un asset manager institutionnel cherche à développer une stratégie multi-asset (equity, taux, FX) basée sur des patterns d’appariement de tendances à moyen terme.
Le modèle utilise une combinaison de séries temporelles techniques (momentum, mean reversion) et de corrélations croisées, ajustées dynamiquement.
Mais les tests classiques posent un problème fondamental : l’historique disponible ne reflète qu’un échantillon restreint de configurations macroéconomiques.
Pour tester la robustesse du modèle, les chercheurs décident d’adopter une approche plus audacieuse : entraîner un GAN (Generative Adversarial Network) sur les données historiques de marchés, en l’obligeant à générer des scénarios alternatifs réalistes mais non observés.
Le générateur produit des séries de prix simulées, mais qui conservent les propriétés statistiques et structurelles des marchés (autocorrélation, clusters de volatilité, copules de dépendance inter-actifs).
Ces scénarios couvrent des régimes rares, comme :
- Une corrélation négative entre actions et taux durable ;
- Une forte volatilité sur les devises émergentes sans propagation aux marchés G10 ;
- Des tendances de marché longues, mais entrecoupées de mini-krachs internes sur certains secteurs.
L’objectif est de backtester non plus une stratégie sur le passé, mais sur une distribution plausible de futurs alternatifs.
À travers ces tests, l’équipe identifie une forte dépendance de la stratégie à certains régimes de corrélation entre actifs.
Elle introduit alors un module adaptatif qui ajuste les poids des signaux selon un regime classifier externe, entraîné à détecter ces changements de régime.
➡️ Résultat : les performances globales deviennent légèrement plus conservatrices, mais nettement plus stables dans les scénarios extrêmes.
Ce cas d’usage illustre parfaitement la puissance des générateurs de données synthétiques pour simuler des réalités non observées, à condition de respecter des contraintes structurelles fortes. Il montre aussi que le backtest devient un outil prospectif de stress intelligence, bien au-delà de la simple validation rétrospective.
Conclusion
Le backtesting, longtemps perçu comme une simple étape de validation ex post dans le cycle de développement des stratégies quantitatives, est aujourd’hui en pleine mutation.
À mesure que les marchés deviennent plus rapides, plus fragmentés, plus sensibles aux données exogènes, il ne peut plus se contenter de rejouer mécaniquement le passé.
Il doit se réinventer en profondeur pour devenir un outil de simulation stratégique à haute fidélité, capable de reproduire les complexités de l’environnement de marché, d’absorber des données toujours plus variées, et de tester la résilience des modèles dans des contextes extrêmes, parfois encore jamais observés.
Construire des stratégies robustes et adaptatives face à l’incertitude
Cette nouvelle génération de backtesting ne se résume pas à un changement d’outillage.
Elle incarne une nouvelle manière de penser le risque et la performance.
Là où l’on cherchait hier à optimiser un PnL moyen sur un historique connu, on cherche aujourd’hui à construire des stratégies robustes, adaptatives, capables de survivre à des régimes inconnus.
Le réalisme d’exécution, l’intégration des données alternatives, la scénarisation probabiliste ou adversariale, et la maîtrise du cycle de vie des données deviennent des prérequis, non plus des options.
Une infrastructure distribuée, modulaire et intégrée au cloud
Cette transformation s’accompagne d’un saut qualitatif sur l’infrastructure.
Le backtest devient un système distribué, modulaire, reproductible, souvent orchestré dans le cloud et intégré aux outils de CI/CD.
Il rapproche les équipes quantitatives, les développeurs et les métiers autour d’un langage commun de rigueur, de transparence et d’agilité.
Il permet de réduire les frictions entre recherche et production, de mieux contrôler le risque opérationnel, et de renforcer la gouvernance algorithmique dans un cadre réglementaire de plus en plus exigeant.
Les défis de l’adoption du backtesting nouvelle génération
Mais cette transition vers un backtesting de nouvelle génération soulève aussi des défis.
Le coût d’infrastructure peut être élevé.
La complexité technique impose une montée en compétence continue.
Et l’adoption de ces méthodes reste inégale entre les acteurs — les pionniers, souvent des structures très technologiques (HFT, prop desks, fonds quant deep-tech), ayant une longueur d’avance sur les acteurs plus traditionnels.
Un instrument de lucidité stratégique, pas une boule de cristal
Il serait toutefois illusoire de croire que le backtesting peut prédire le futur.
Il ne le pourra jamais.
Mais il peut, s’il est bien conçu, nous aider à mieux comprendre l’espace des possibles, à identifier les angles morts d’un modèle, à détecter les signaux faibles d’un échec potentiel.
Il devient ainsi un instrument de lucidité stratégique, un filtre contre l’optimisme naïf des courbes de performance parfaites, et un levier d’innovation continue dans un univers financier en perpétuel changement.
Repenser le backtesting : anticiper les conditions d’échec
En définitive, repenser le backtesting, c’est poser une question centrale : non pas “est-ce que cette stratégie marche ?”, mais “dans quelles conditions cette stratégie cesse de marcher — et que pouvons-nous faire avant que cela n’arrive ?”
Chez MARGO, nous accompagnons les acteurs financiers dans la conception et l’industrialisation de leurs environnements de backtesting, en combinant expertise quantitative, excellence logicielle et maîtrise des infrastructures cloud.
Pour en savoir plus sur nos offres et découvrir nos retours d’expérience, contactez-nous ici.
À lire ensuite :
Comment diversifier son portefeuille d’actions face aux événements macroéconomiques

