
Introduction : Pourquoi cette décision est stratégique en 2025
En 2025, l’intégration de l’intelligence artificielle générative dans les entreprises ne relève plus de l’innovation exploratoire, mais d’un véritable virage stratégique. Entre le fine-tuning de modèles de langage et l’approche RAG (Retrieval-Augmented Generation), les directions techniques et data sont confrontées à un dilemme structurant. Ce choix impacte directement le coût de possession, la flexibilité métier, la scalabilité et la traçabilité.
Face à des corpus de documents en constante évolution, des exigences réglementaires croissantes, et des besoins métiers de plus en plus précis, comment faire le bon choix ? Cet article propose une analyse comparative complète, enrichie de retours d’expérience et de recommandations concrètes pour aider les CTO, CDO et décideurs métier à choisir la bonne stratégie IA.
Fondamentaux techniques : Fine-tuning vs RAG
Qu’est-ce que le RAG ?
Le RAG (Retrieval-Augmented Generation) combine deux capacités : la recherche intelligente d’information dans une base documentaire et la génération de texte à partir des résultats pertinents.
Le modèle LLM n’est pas modifié, mais augmenté dynamiquement par des données actualisées, filtrées selon la requête utilisateur.
Qu’est-ce que le Fine-tuning ?
Le fine-tuning consiste à adapter un modèle de langage pré-entraîné (comme GPT ou LLaMA) à un domaine spécifique en l’entraînant sur un jeu de données métier.
On modifie les paramètres internes du modèle pour qu’il assimile des terminologies ou comportements propres à une entreprise.

Évolution du RAG vers un standard industriel en 2025
Du POC à la production : maturité technologique et adoption
En 2023-2024, le RAG était encore souvent limité à des POCs. En 2025, il est devenu un cadre d’architecture standard, intégré dans des pipelines MLOps/LLMOps avec supervision, versioning et contrôle qualité.
RAG as Infrastructure : mutualisation et gouvernance documentaire
Cette approche favorise une gouvernance centralisée du savoir, tout en permettant la réutilisation de briques techniques pour différents cas d’usage (support, RH, juridique).
Elle accélère le time-to-value, réduit les coûts et renforce la traçabilité.
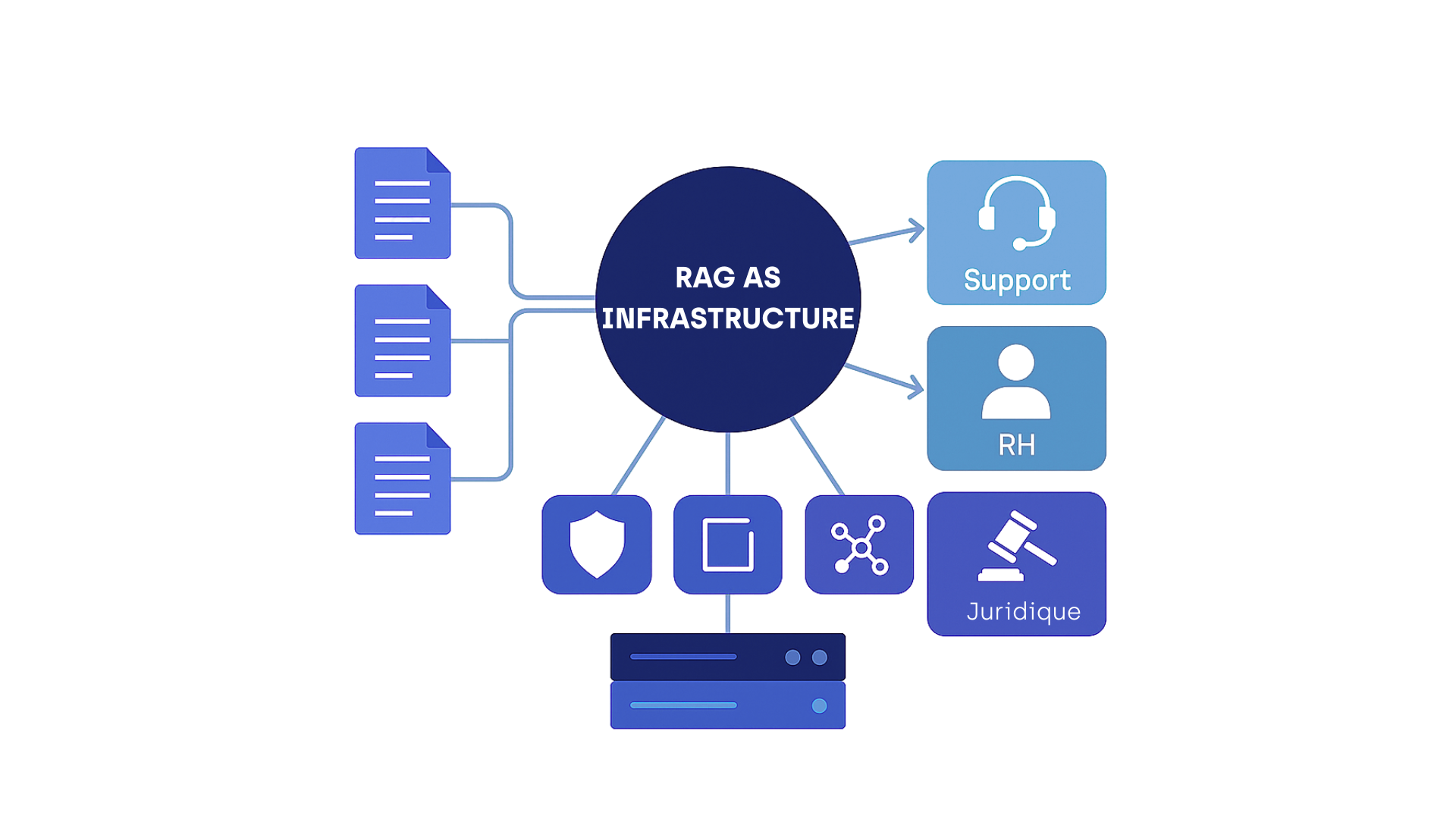
Architecture d’un RAG “enterprise-grade” : les 5 briques essentielles
Un RAG robuste repose sur une architecture modulaire et alignée avec les exigences métier. Voici les cinq briques essentielles à toute mise en production sérieuse.
Ingestion documentaire & prétraitement
La qualité du système RAG dépend d’abord du corpus d’entrée. Il faut assurer un parsing intelligent, un enrichissement sémantique, une normalisation des formats et un versioning rigoureux des documents.
Indexation vectorielle hybride & métadonnées
L’approche hybride (dense + sparse) permet d’optimiser la pertinence des réponses. En y ajoutant un usage intelligent des métadonnées (date, auteur, service), on obtient un filtrage métier très fin.
Orchestration intelligente du retrieval
Le système de retrieval devient adaptatif, grâce à des mécanismes comme le reranking, le fallback contextuel ou encore la prise en compte du profil utilisateur.
Génération contrôlée et contextualisée
Le modèle LLM doit respecter un ton éditorial, une structure de réponse et des règles métier. L’ajout d’un grounding strict permet d’éviter les hallucinations et renforce la conformité des réponses générées.
Observabilité et boucle de feedback
Une plateforme RAG doit intégrer un monitoring des hallucinations, une journalisation des requêtes, et des outils de feedback utilisateur pour améliorer en continu la qualité des réponses.
RAG vs Fine-tuning : comparaison des avantages et inconvénients
Le choix entre RAG et Fine-tuning repose sur des critères opérationnels, techniques et économiques. Voici les différences majeures à connaître :
| Critère | Fine-tuning | RAG |
|---|---|---|
| Coût | Élevé (entraînement, infra) | Modéré (pas de réentraînement) |
| Flexibilité | Faible (réentraînement requis) | Forte (maj du corpus possible à tout moment) |
| Maintenance | Complexe (nécessite experts IA) | Simplifiée (pipeline documentaire) |
| Traçabilité | Faible (modèle boîte noire) | Forte (sources documentaires visibles) |
| Fréquence de mise à jour | Faible | Haute |
Grille de décision business 2025 : 4 critères clés
En 2025, le choix entre fine-tuning et RAG ne doit pas se faire uniquement sur des critères techniques. Il doit s’appuyer sur une analyse des besoins métiers concrets, des contraintes documentaires, et des enjeux réglementaires. Voici les 4 critères business les plus déterminants, chacun illustré par un éclairage opérationnel :
Fréquence de mise à jour documentaire
Question à se poser : À quelle vitesse évoluent mes contenus métier ?
RAG recommandé si : votre documentation est en constante évolution (politiques RH, procédures IT, fiches produits, guides internes).
Chaque changement de document peut être intégré sans réentraîner un modèle.
Les réponses générées sont toujours à jour, tant que le corpus est mis à jour.
Fine-tuning déconseillé si : les contenus changent souvent, car chaque mise à jour nécessite un réentraînement coûteux du modèle.
Exemple :
Une entreprise SaaS qui met à jour son produit tous les mois a besoin que son copilote interne réponde avec les dernières fonctionnalités. Le RAG permet de rester pertinent, sans reconfigurer le système.
Stabilité vs volatilité des cas d’usage
Question à se poser : Mes cas d’usage sont-ils bien définis et durables, ou évolutifs ?
Fine-tuning recommandé si :
Classification automatique de documents
Réponses standardisées à un volume massif de requêtes
Génération de contenus normés
RAG recommandé si :
Le besoin est variable ou exploratoire, comme :
Recherche contextuelle dans des rapports
Aide au diagnostic métier
Accès à des connaissances dispersées ou sectorielles
Une équipe juridique qui interroge des bases de jurisprudence sur des thématiques variées bénéficiera du RAG pour adapter dynamiquement les réponses à chaque situation.
Niveau de contrôle exigé sur les réponses
Question à se poser : Est-ce que je dois pouvoir justifier ou prouver chaque réponse générée ?
RAG recommandé si :
Vous avez besoin d’un haut niveau de traçabilité
Vous devez montrer la source précise utilisée pour générer la réponse
Vos utilisateurs ont besoin de vérifiabilité métier (ex. : compliance, fiscalité)
Fine-tuning déconseillé si :
Il est difficile de contrôler les justifications du modèle (réponses apprises mais non sourcées)
Exemple :
Dans une banque, une réponse à une question réglementaire doit toujours renvoyer à un article ou document précis. Le RAG peut afficher ce document avec la réponse, ce que le fine-tuning ne permet pas aisément.
Contraintes réglementaires et sécurité
Question à se poser : Où mes données doivent-elles être hébergées ? Quel niveau de confidentialité est requis ?
RAG recommandé si :
Vous avez des contraintes de souveraineté des données
Vous souhaitez contrôler l’hébergement (cloud privé ou on-premise)
Vous utilisez des modèles open source comme Mistral ou LLaMA 3 pour garder le contrôle
Fine-tuning moins adapté si :
Vous dépendez d’un modèle fermé hébergé à l’extérieur (ex. : GPT-4 sur Azure/OpenAI)
Vous traitez des données sensibles non exportables
Exemple :
Une administration publique ou une entreprise de défense peut préférer un RAG avec LLaMA 3 sur infrastructure interne, plutôt qu’un fine-tuning sur un modèle hébergé à l’étranger.
Cas d’usage typiques selon l’approche
Cas d’usage propices au Fine-tuning
Le fine-tuning est particulièrement pertinent dans les contextes suivants :
Chatbots spécialisés dans des environnements fermés, comme les assistants médicaux ou juridiques ayant besoin d’un langage très spécifique.
Génération de contenu normatif, comme les réponses aux appels d’offres ou les synthèses réglementaires.
Systèmes embarqués, où la connexion à une base externe est impossible ou risquée.
Applications B2C à grande échelle, où l’optimisation des performances à bas coût est primordiale.
Cas d’usage idéaux pour le RAG
Le RAG excelle dès qu’il faut industrialiser l’accès à un savoir métier évolutif, notamment dans :
Le support interne (RH, IT, juridique)
Les copilotes métier pour la gestion documentaire
La veille réglementaire ou concurrentielle
L’onboarding de nouveaux collaborateurs via des FAQ dynamiques
Identifier le bon usage au bon moment est un exercice stratégique. Les consultants IA de MARGO sont justement là pour vous aider à cartographier vos cas d’usage et définir une feuille de route pragmatique.
Étude de cas : MargoZilla, assistant RAG interne
Chez Margo, l’assistant IA MargoZilla a été conçu pour soulager les équipes support. Il répond automatiquement aux questions des collaborateurs sur les sujets RH, IT, formations ou événements internes. Connecté à Google Drive, il délivre des réponses sourcées et contextualisées directement via Google Chat.
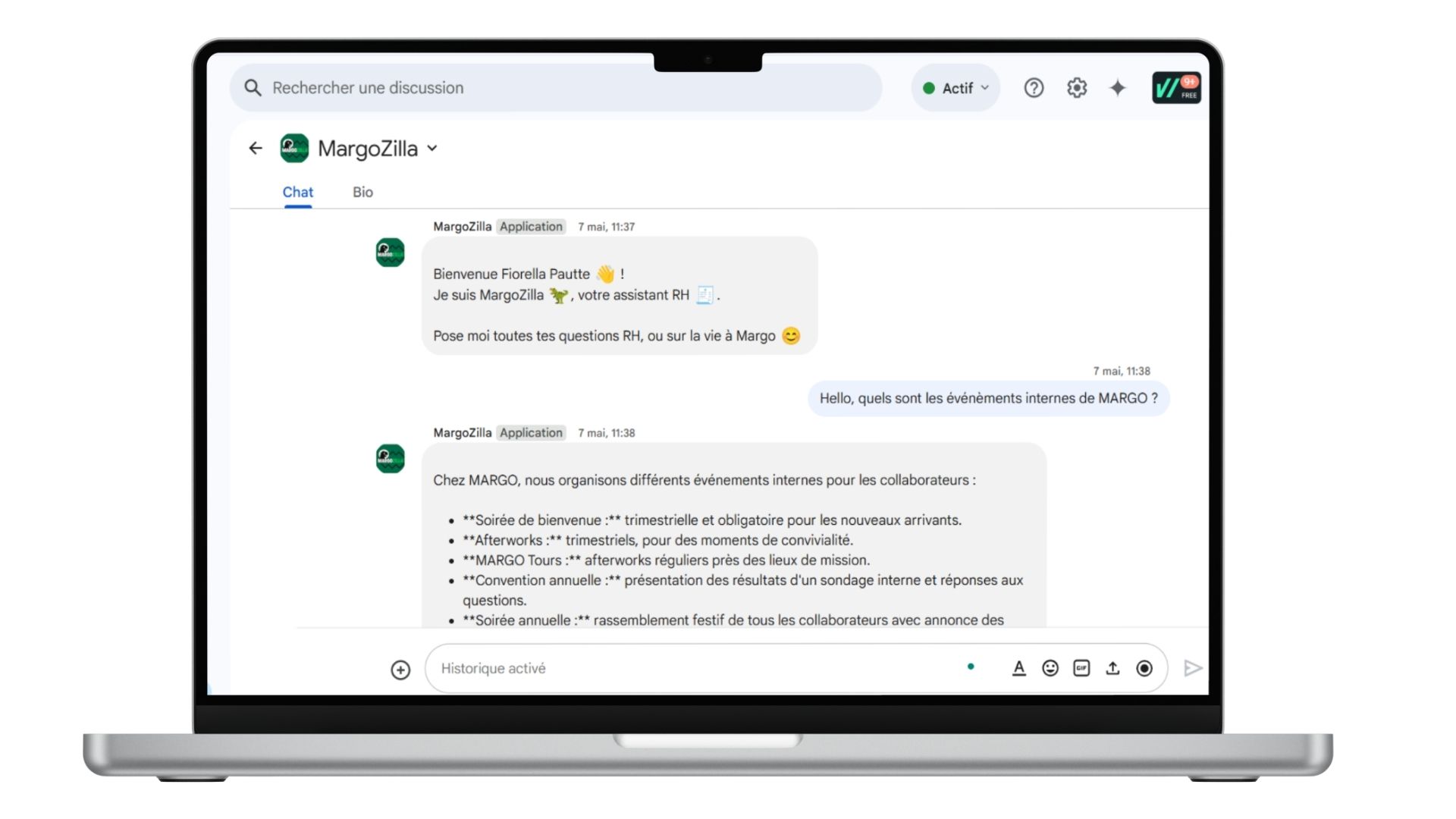
Contraintes majeures :
Hétérogénéité du corpus documentaire
Besoin de filtrage rigoureux : pour éviter les hallucinations, fuites d’informations sensibles par exemple
Intégration fluide dans Google Workspace
Résultats :
Réduction des sollicitations RH/IT
Adoption rapide grâce à l’UX simple
Gain de temps réel pour les équipes
Leçons apprises du terrain
Structuration du corpus = facteur n°1 de qualité
Métadonnées = filtrage fin et réponse pertinente
Pipeline automatisé = données toujours fraîches
Intégration métier = adoption facilitée
Écosystème technologique RAG en 2025
L’industrialisation des projets RAG en 2025 repose sur une chaîne technologique robuste, modulaire et interopérable. Plusieurs outils et frameworks se sont imposés comme des standards de facto, chacun couvrant un maillon clé de l’architecture.
LangChain : orchestration intelligente pour les workflows LLM
LangChain est devenu le framework de référence pour construire des chaînes d’appels entre un LLM, un moteur de recherche, une base de données ou une API.
LangServe / LangSmith : outils intégrés pour exposer des endpoints API et monitorer les chaînes en production.
- Modularité extrême (agents, outils, memory…)
- Interconnexion avec tous les grands modèles (OpenAI, Anthropic, Hugging Face…)
- Orchestration avancée de tâches séquentielles ou parallèles
LlamaIndex : gestion avancée et dynamique du corpus
Anciennement GPT Index, LlamaIndex est un outil spécialisé dans la connexion entre un corpus documentaire et un LLM. Il excelle dans la construction d’index performants et à jour.
- Ingestion intelligente de données non structurées
- Chunking personnalisé et contextuel
- Graphes de documents interconnectés
Haystack : pipeline NLP robuste, traçabilité native
Développé par Deepset, Haystack est un framework open source axé sur la recherche sémantique, la génération augmentée et la traçabilité.
- Support natif des architectures RAG
- Monitoring des performances, explicabilité des résultats
- Intégration facile avec Elasticsearch, OpenSearch, Qdrant
Qdrant, Weaviate, FAISS : moteurs vectoriels au cœur du RAG
Ces bases vectorielles sont les “cerveaux” du système RAG. Elles permettent de transformer des documents en vecteurs numériques, puis de retrouver les plus pertinents lors d’une requête.
- Qdrant : Open source, filtrage avancé, cloud-native – Support métier contextuel
- Weaviate : Graphs intégrés, schema-first, API REST+GraphQL – Recherche relationnelle
- FAISS : Ultra-performant, support GPU, simple – Cas haute performance, on-premise
Critères business pour choisir :
Latence : réactivité dans les interfaces utilisateur
Filtrage : capacité à croiser vecteurs + métadonnées
Coût d’infra : hébergement optimisé
Conformité RGPD : cloud souverain vs cloud public
Scénarios on-premise : FAISS et Qdrant excellents candidats
Convergence IA : vers des assistants cognitifs autonomes
L’avenir du RAG ne s’arrête pas à la génération de texte contextuel. On assiste à une fusion avec d’autres approches IA émergentes, qui le transforment en véritables copilotes métiers intelligents.
Agents LLM + RAG : vers l’automatisation des workflows complexes
Les frameworks comme LangChain Agents, CrewAI ou AutoGPT permettent à des LLM de devenir des agents autonomes, capables de :
Planifier une séquence d’actions (recherche + analyse + réponse)
Appeler des APIs externes, comme une base CRM ou un ERP
Agir en fonction du résultat, comme rédiger un rapport, déclencher un ticket, générer une recommandation
Exemples de cas d’usage :
Générer automatiquement un plan de formation personnalisé à partir des entretiens RH
Compiler un rapport d’activité à partir de logs métiers et emails
Multimodalité : RAG au-delà du texte
L’intégration des capacités multimodales transforme le RAG en outil polyvalent et immersif :
Lecture de PDF scannés, plans, schémas
Traitement d’images (ex. : manuels industriels illustrés)
Génération de contenus enrichis (graphes, diagrammes, interfaces visuelles)
Exemples de cas d’usage :
Maintenance industrielle (reconnaître une pièce sur photo et générer une fiche technique)
Support technique (analyser un message vocal et retrouver la bonne documentation)
Live RAG + Graphes de connaissances (Knowledge Graphs)
Le “Live RAG” connecte la génération augmentée à des sources de données temps réel : bases SQL, APIs internes, outils de BI, etc.
Objectif : produire des réponses hybrides, combinant :
Synthèse textuelle
Données chiffrées ou métriques en direct
Knowledge Graphs : permettent de structurer la connaissance (entités, relations), rendant les réponses plus précises et déductives.
Cas d’usage privilégiés :
Pilotage commercial (générer une synthèse d’un client + son historique + ses KPI actuels)
Diagnostic financier (rapprochement entre des règles comptables et des chiffres live)
En résumé
Le RAG en 2025 ne se conçoit plus comme un simple outil d’accès documentaire, mais comme un socle stratégique pour construire des assistants intelligents, fiables, adaptables et interconnectés. Il s’inscrit désormais dans un écosystème technologique mature, au croisement du NLP, de la data engineering, des agents autonomes, et des graphes de connaissance.
Besoin d’un copilote IA dans votre organisation ?
Envie d’industrialiser un POC ou d’optimiser un système RAG existant ?
Nous sécurisons votre delivery IA, alignons la technologie sur vos enjeux, et accélérons votre transformation data.
👉 Contactez nos expert IA

